This article was automatically translated from the original Turkish version.

Year(Date) | 2014-09-04 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
Developer(s) | Oxford Visual Geometry Group | ||||||||
Variants | VGG19 VGG16 | ||||||||
Performance | ImageNet Top-1 ~%71.5 | ||||||||
Number of Parameters (Approximate) | ~143.7M | ||||||||
Number of Layers | 19 | ||||||||
Input Size | 224x224x3 | ||||||||
Base Component | Consecutive 3×3 convolution filters | ||||||||
Model | VGG 19 | ||||||||
VGG19 is a deep convolutional neural network developed for visual recognition tasks. Proposed in 2014 by the Oxford University Visual Geometry Group (VGG), this model is a deeper variant of VGG16. Comprising a total of 19 layers, its architecture aims to learn more complex patterns by employing small convolutional filters (3×3) in a stacked configuration.
The VGG19 architecture is based on design principles similar to those of VGG16. Each convolutional layer uses 3×3 filters, which are arranged consecutively. Following each convolutional block are max pooling layers. The final section consists of three fully connected layers.
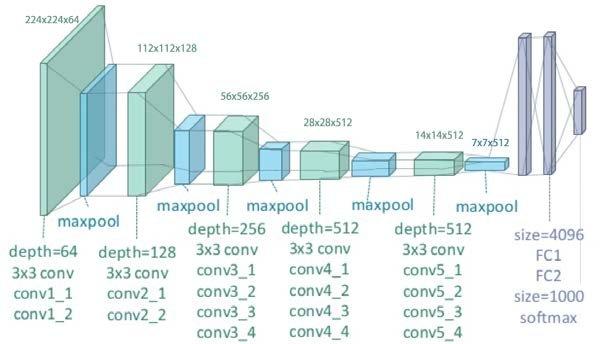
VGG19 Architecture (
The VGG19 architecture enhances feature extraction by achieving deeper layers through consecutive small filters.
VGG19 contains a total of 19 learnable layers: 16 convolutional layers and 3 fully connected layers.
VGG19 is widely used in various visual tasks, primarily image classification:
Gümele, Kaan, and Muhammet Sinan Başarslan. “Oral Cancer Classification with CNN Based State-of-the-Art Transfer Learning Methods.” *Black Sea Journal of Engineering and Science* 8, no. 1 (January 2025): 94–101. https://doi.org/10.34248/bsengineering.1528581.
Simonyan, Karen, and Andrew Zisserman. “Very Deep Convolutional Networks for Large-Scale Image Recognition.” *arXiv* preprint arXiv:1409.1556 (2014). https://arxiv.org/abs/1409.1556.
Zheng, Yufeng, Clifford Yang, and Aleksey Merkulov. “Breast Cancer Screening Using Convolutional Neural Network and Follow-up Digital Mammography.” Ed. Amit Ashok, Jonathan C. Petruccelli, Abhijit Mahalanobis, and Lei Tian. *Computational Imaging III*, May 2018. https://doi.org/10.1117/12.2304564.
Year(Date) | 2014-09-04 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
Developer(s) | Oxford Visual Geometry Group | ||||||||
Variants | VGG19 VGG16 | ||||||||
Performance | ImageNet Top-1 ~%71.5 | ||||||||
Number of Parameters (Approximate) | ~143.7M | ||||||||
Number of Layers | 19 | ||||||||
Input Size | 224x224x3 | ||||||||
Base Component | Consecutive 3×3 convolution filters | ||||||||
Model | VGG 19 | ||||||||
VGG19 Architecture
Layer Structure
Features and Advantages
Disadvantages
Applications